 LinkedIn
LinkedIn  Contact Us
Contact Us The Evolution of the Data Center
Written by Phil Harris, CEO at Cerio

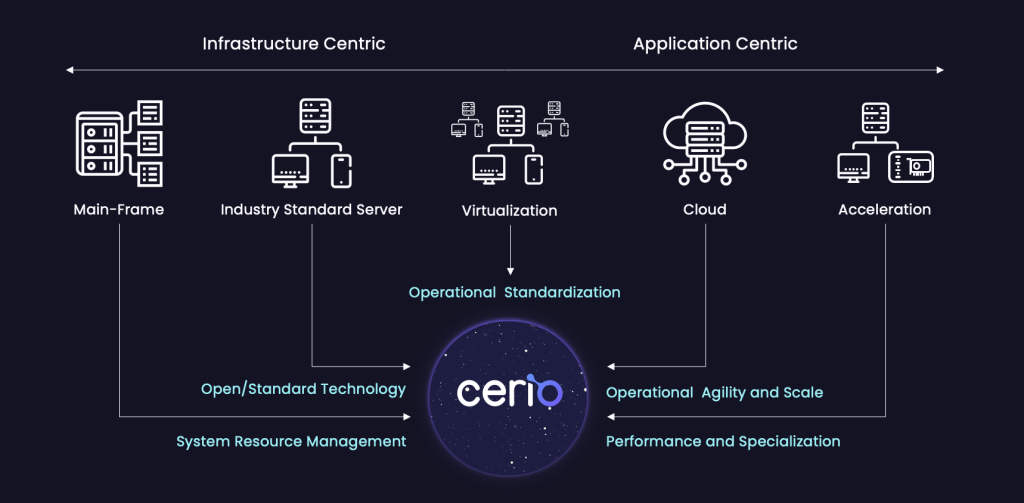
Over time, we’ve seen five main eras of the data center – each one provided innovation, but also resulted in a trade-off from what the previous era introduced.
Reflecting on the different eras, we uncover advantages that address current data center challenges. In the present landscape, fine-grained system resource management, integration of off-the-shelf components without proprietary constraints, standardization for optimal resource allocation, operational agility, scalability, and innovative accelerators are crucial to our success. We must incorporate all those features when building the next generation of data centers. That’s why it’s time for a new way of thinking about how we build and operate data centers.
Generative AI has created an inflection point in data centers where operators and cloud service providers are having to make difficult choices about how they’re deploying technology due to the types of workloads being run. A lot of this is due to the way we’ve built systems in the last 30 years since moving away from mainframes. We’ve been focused on a CPU centric system model as the central point of how all applications have been designed, developed, and run. While the advent of GPUs and other augmented accelerators have provided better results in terms of the design, development, performance and scale of those applications, the way we’ve been building data centers is no longer sustainable.
For the last 20-30 years, due in part to our power consumption, the ability to run data centers has been getting harder and more expensive. It’s becoming extremely difficult operationally, commercially, and technically to build the scale of data centers we need for the workloads we want to deploy. The industry standards server model has had a good run for the last 30 years, but it’s time to start looking at new ways of approaching some large problems.
The workloads have been the main driver as to why we’re at an inflection point, but it’s more than that. We tend to swing back and forth between centralizing things within on-premise data centers or within the enterprise, and then decentralizing them and moving them out to the cloud. For a lot of reasons that’s become a bit of a revolving door.
More companies want to repatriate workloads for a variety of reasons – some of which are classical data privacy and data domain control issues, while some are simply because people want to develop very specific versions of large language machines, for example. For generative AI or financial services compared to other vertical markets, the cost of doing that in the cloud is expensive. So as people are developing, deploying, and figuring out how to use this technology in their enterprise, they want it on-prem, which is leading people to pause.
Operational agility and operational scale were good reasons to move to the cloud. Now, we want to replicate those capabilities in our own data centers but you can’t build a data center at the scale that cloud can.
Requiring a complete rethink involves the way we deploy data centers, how we build systems, and how to operate those systems so that we can maximize the agility of the extremely expensive resources we have both on-prem and in the cloud. This applies to anyone who runs a data center to deliver workloads, applications, and services to their customers.
Why Can’t Today’s Networks Solve the Problem?
Having spent a lot of my career at a very large networking company, we were always focused on how systems talk to other systems – that could be in a typical client server model, or a multi-tiered enterprise workload. We weren’t looking at how the system itself was built, but how we connected between systems. Now, we must look in a different way at how the system level model operates.
One of the problems is that we’ve got a lot of workloads with a lot of standard operating systems and with many drivers – things like accelerators, GPUs, resources, memory, storage, and we’re not going to change all those overnight.
Achieving a challenging task without causing disruption requires a strategic approach. The key is to dive into how the system is built and scale it effectively to enhance agility and flexibility in the model without altering the function of existing workloads, except to leverage additional resources. Over time, as we solve these system-level problems, and networking technology maintains its classical role, we’ll begin to see how these two worlds can come together.
The Eras
Mainframes
The evolution in computing started in the ’90s with the mainframe era, when we transitioned from a timeshare computer at an academic institution to widespread availability for enterprises. We gained massive compute power with very fine-grained system resource management that allowed you to allocate the right resources for that workload for different jobs, but it was very expensive and complicated. This was the earliest precursor to what we call virtualization today.
Industry Standard Servers
Then we moved onto the industry standard server, where it was now much cheaper to put compute resources into a data center with more standardized, off-the-shelf components.
We had central processors that provided common ways of building applications that were vendor agnostic. Over time that became more open source and open standard, providing the ability to do things at a different scale and a different price point, while still at a unit level of capacity and resources. This meant that we lost some of the flexibility that the system resource model of the mainframes gave us. However, the tradeoff was that we could do this faster and cheaper, while scaling as needed, as opposed to starting with a large system model design.
This is when we saw the proliferation of the independent software vendor market, and open source became the critical way we write code and operating systems, lasting for about 30 years.
Virtualization
In the early 2000’s, virtualization came back. We leveraged that industry standard software to provide better operational standardization. This meant you could offer a standard system as a virtual machine, independent of the actual system it was running on.
Virtualization reduced some of the cost of providing services to customers by standardizing not only the operating systems and workloads, but because it was more portable across machines and therefore provided a lot of flexibility.
Cloud
Then cloud came along. Cloud adoption was primarily driven not by its technology, but by the promise of operational and commercial agility, along with the unprecedented scale that you couldn’t otherwise achieve at that time.
Acceleration
As an outcome of the operational agility and scale that cloud provided, a much larger developer community started to emerge. This was because there was easier access to infrastructure and systems that allowed you to build new applications. Independent software vendors were no longer the primary source of application development and while not a new concept, one of the big trends to come out of this period was artificial intelligence.
It became evident that the CPU in the servers had been generalized to the extent that they were suitable for numerous applications, but they were insufficient for the specific calculations and processing required for AI. This meant that the applications didn’t keep up with the scale and complexity of AI workloads – but there was a new technology that did.
GPUs became the new accelerator of choice as they were instrumental in offloading and accelerating AI workloads, more than what could be done with traditional CPU-based systems.
This emphasis on accelerated systems is pivotal for driving advancements in generative AI, and it’s that acceleration that’s pushing the boundaries of the initial system models we’ve been working within the cloud and on-prem over the last 30 years.
What’s Next?
Each of the five eras of the data center had core value for their time, but each one was a trade-off from what the previous had given us.
Looking at those eras, we can draw from their benefits to solve the problems we’re facing today. We still need fine-grained system resource management, the ability to use off-the-shelf components that don’t lead us to proprietary models, standardization to repeatedly provide the right resources for the right workloads, the operational agility and scale to build more powerful workloads, and a new generation of accelerators that make our workloads perform in more complex ways. We need to bring all those values into how we build the next generation of data centers.
So, how do we do that at the scale and agility that we need to? As things continue to evolve at such a rapid pace, we must look at a different commercial and operational model because the scale of the data center we would need to build for every enterprise will start looking a lot like a cloud – and that’s not feasible.
We need to accommodate different types of workloads and resources – meaning more distributed memory and faster accelerators. They’re no longer just a resource within a system, they are a system.
It’s time for a new way of thinking about how we build and operate data centers.
Composability
Meet composability. Composability means that you’re not limited to a solid-state system that you designed at the time of procurement. Previously, you filled out a purchase order, specified what that machine would look like, received a price and delivery date – and that was it. That system would be put into your data center, and for the duration of its depreciation cycle or useful technology life, that was what you had.
The inflexibility of how we built systems was driven by the lack of practical methods for providing an expanded universe of capabilities in real time. If your CPU technology cycle differed from that of your GPUs, memory, or storage; you couldn’t deploy, refresh, and innovate against each of those with the old system model. Composability lets you separate all those things and deconstruct the system model so that when you want to deploy a system, you can assemble it in real time.
Composability lets you decide on components and refresh them as needed, while ensuring that a failure in your data center doesn’t bring down the entire system to fix a single device or resource. Components are physically disaggregated but logically recomposed, and achieving this requires cutting-edge technology that until now hasn’t been available in the market.
The Cerio platform is dedicated to enabling the next generation of data centers. Composability is a key method that provides significantly enhanced operational agility, and the ability to scale beyond the limitations imposed by the original single system model.
With Cerio, you aren’t limited by environmental, technical, operational, or managerial aspects of the standard system model when building a composed system. This guarantees minimal disruption to data center operators by seamlessly integrating into existing management and IT tools and eliminates the need for extensive training.
Cerio’s technology is transparent to the workloads but provides a scale fabric that allows us to span the entire data center, not just one or two racks. Our technology is built this way to provide access to resources at the scope of the entire data center. You need to be able to discover them, understand their capabilities, then assemble them into the system you’re deploying for whatever workload, service, or customer.
In my next blog, I’ll explore the business and technical advantages of this data center system model.