 LinkedIn
LinkedIn  Contact Us
Contact Us How Switchless Networks Unlock Storage Networks at Scale
The performance of your storage infrastructure is only as good as the network it’s connected to, and that’s a problem.
At the recent Samsung Tech Day, Rockport CTO Matt Williams presented to a broad audience of customers, partners, and Samsung employees, explaining that distributed storage performance is only as performant as the network supporting it. He also detailed how Rockport’s switchless networking fabric enables a fully distributed, multi-petabyte storage capability for Samsung’s newly released Poseidon product. It was a showcase for how a next-generation networking start-up like Rockport improves storage latency, bandwidth, and IOPS at scale. Below are the key elements of Matt’s presentation.
Storage Performance = Network Performance
Traditional switch-based networks that organizations use to connect storage devices to the servers are, by nature, switch intensive. Each layer of switches makes the architecture more complex and inherently adds congestion as the traffic competes for ports. This congestion, in turn, leads to latency and packet loss. All of which mean it takes longer to move data in and out of storage.
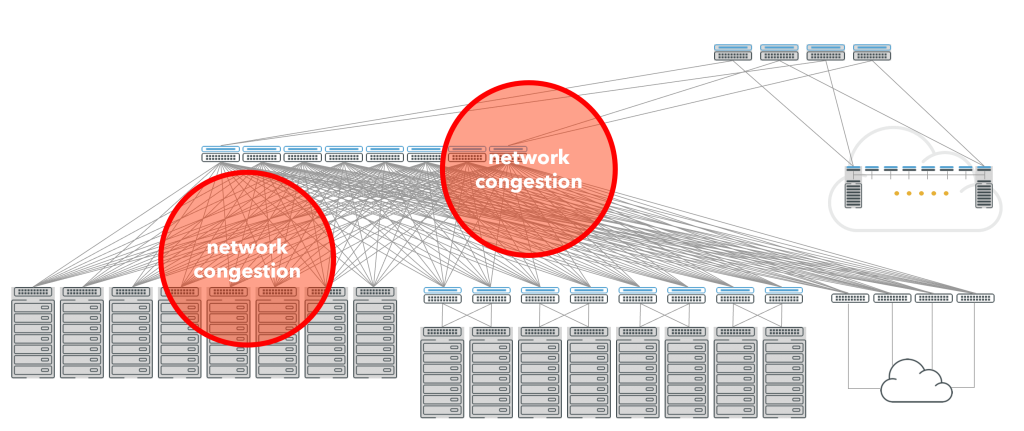
Figure 1: Congestion is inherent in centralized switched networks.
Compounding this issue, growing networks reach a natural tipping point when all available ports are occupied so they run out of capacity to add any more storage devices without adding another layer of switches, which necessitates rewiring the entire network. This, in turn, means that these decades-old switch-based networks have issues with scaling.
Don’t blame the switch, blame the architecture
Switches themselves aren’t the root cause of the issues, rather it’s the spine-and-leaf architecture of centralized switching that causes all this pain. In a typical scenario, servers connect to a flash-based storage array through a switch-based network. The storage array itself is very high performance, has very high IOPS and low-latency access, and the server is also high performance. The problem is that network in the middle, which adds latency and jitter (hundreds or thousands of microseconds) which is very detrimental to storage performance.
The bottom line for storage environments is network performance limits storage performance with high tail latency, inconsistent IOPS, and poor throughput, making it challenging for operators to enjoy the full capabilities of their chosen storage solution. These same issues will also be felt – to an even greater degree – by hyperscalers due to the size and complexity of the distributed storage solutions they build. It doesn’t matter how fast the storage is, the network is the limiting factor.
Ditching the Switch
If using switches in a spine and leaf (fat tree) topology is a primary contributor to poor storage performance, then alternatives should be considered. The fastest supercomputers in the world have moved to a direct-connect architecture that removes centralized switches in favor of a distributed environment that puts switching capabilities inside each node and forms direct connections between devices.
Taking centralized switching out of the equation also has the advantage of removing the artificial break points that occur when scaling up a network. If a data center wants to deploy more storage, it’s very easy to do so without worrying about if there is spare capacity in a centralized switch. This enables data centers to scale in place as needed.
Democratizing Switchless Networking with Rockport
Rockport’s direct interconnect solution adopts the same concepts used in the world’s fastest supercomputers, in a way that is easily accessible so can be deployed without specialized training or lengthy deployment times.
To deploy a Rockport network, operators plug a network card into the servers and storage enclosures, connect a passive unpowered cable from the cards to a Rockport SHFL, which is pre-wired with supercomputer networking topologies.

Figure 2: A Rockport Network-enabled storage solution.
The Rockport Network Operating System (rNOS) and the Rockport Autonomous Network Manager (ANM) take care of the rest, making the network self discovering, self configuring, and self healing, as well as providing deep insights into what’s happening in the network on a per-job or per-device basis.
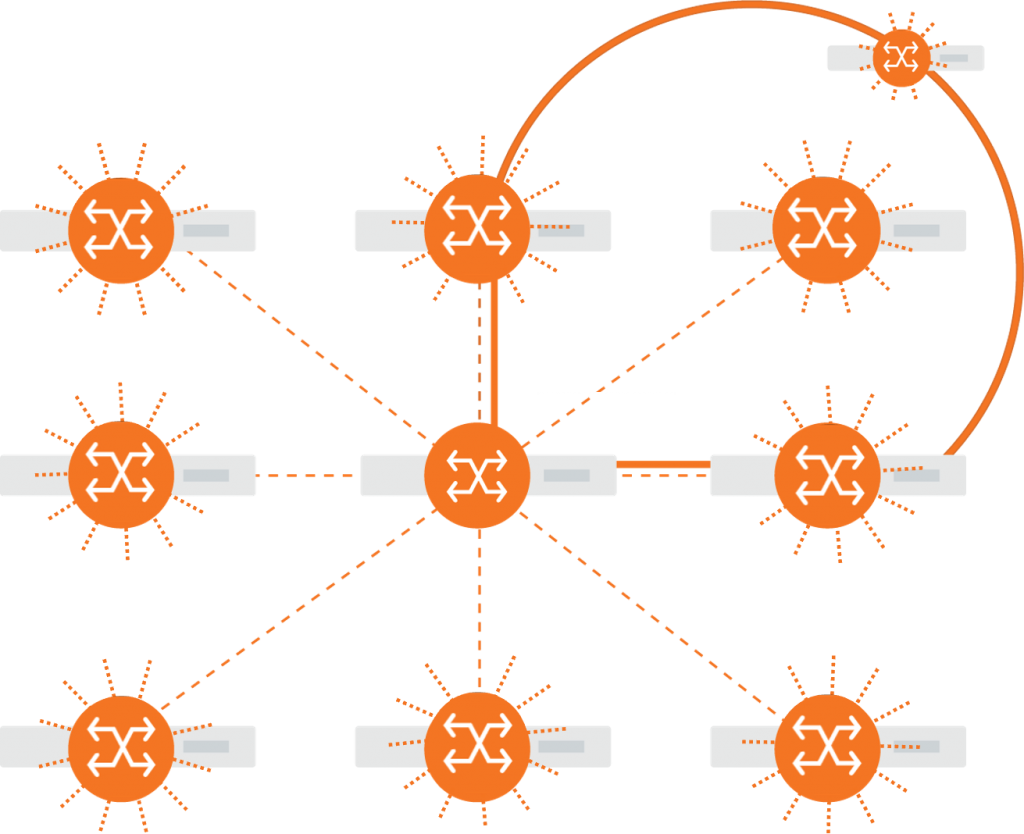
Figure 3: Rockport Networks architecture features directly connected nodes, distributed switching, very high path diversity.
The solution creates a large mesh topology between the connected nodes, with very high path diversity, inherent resiliency, excellent performance at scale with consistent performance, regardless of load. Critically for storage providers, our technology changes very little from the host point of view, by providing a standard Ethernet host interface. The network supports all major standards, including RoCE, TCP, UDP, NVMe-oF, NVMe-over-TCP, the major difference from traditional networks being excellent performance at scale under load.
Proof in the pudding
Customers who have installed a Rockport Switchless Network and run benchmark tests have found their workload completion times are on average 28% faster and they experience 3.5 times less latency in the network, all while under load.
In terms of performance for storage, Rockport removes the bottleneck the network traditionally imposes. The network has very low latency, very low jitter, they’re naturally lossless and have very good throughput. That means storage can maintain the very high IOPS needed for high-performance storage applications.
If you’re a hyperscaler or enterprise who finds the inherent characteristics of switched networks are negatively affecting the performance of your multi-petabyte distributed storage arrays, consider Rockport. Our switchless network architecture provides a real opportunity to improve storage latency, bandwidth, and IOPS, particularly at scale and in a way that’s very easy to deploy, is power efficient and provides excellent results even under heavy load.